SEO Patterns of Online Dictionaries
Dictionaries are a goldmine of SEO Patterns. They have insane amount of pages. Competition is fierce and the type of keywords they target are one of the biggest bucket of popular informational keywords. Plus they drive insane amount of traffic. We will investigate how.


I was always amazed by the amount of traffic online dictionaries are driving by optimizing their database of words, synonyms, and example sentences.
So dictionaries were a no-brainer to go after when I was selecting the candidates for the SEO Patterns series.
Dictionaries or reference sites are also part of most of the Google Core Update Analyses partially because of their size, and partially because often they come out as winners.
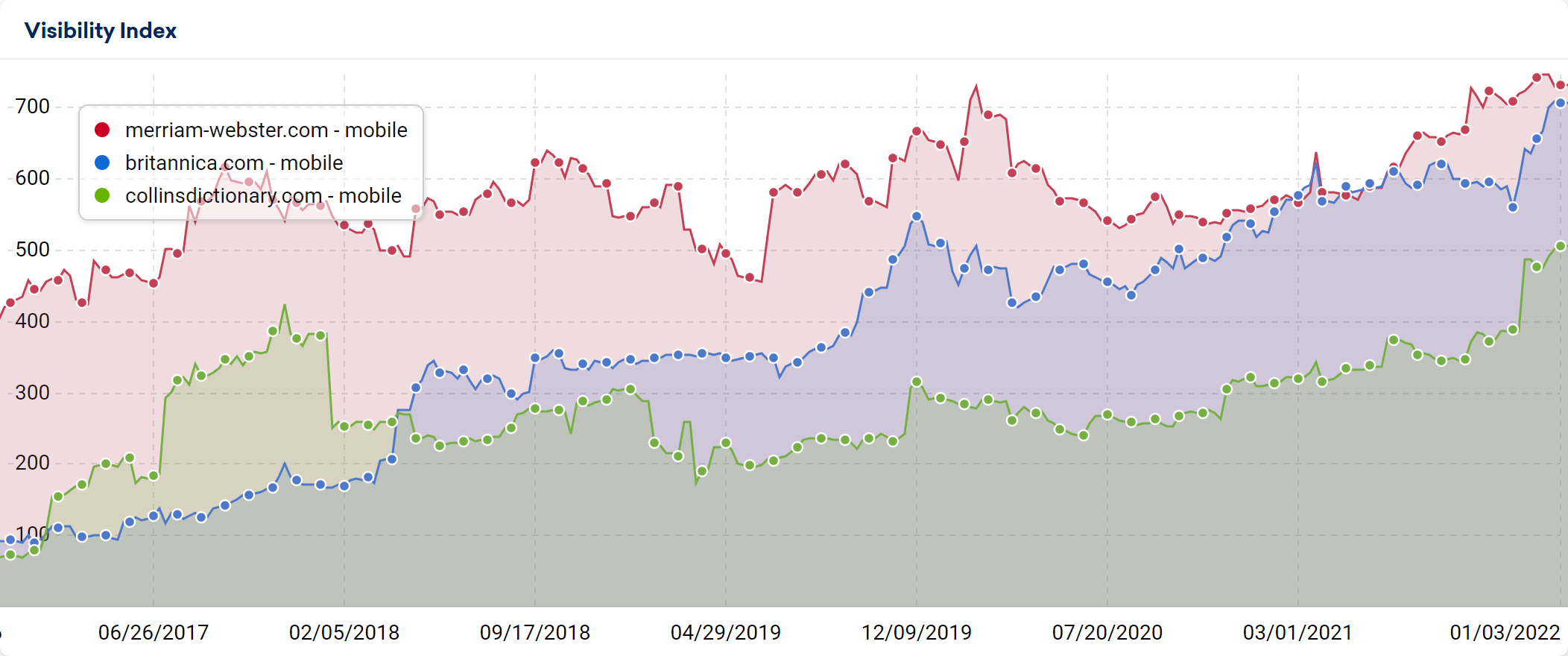
What enables some of these sites to sit on top of the search results while even increasing their visibility in search over time?
I was searching for clues to answer these questions.
Here are what I found. 👇
Top Dictionaries
There are more dictionaries than I could collect as a list without writing a word about them. So to find the best candidates for my SEO Patterns Quest I have chosen a simple method with some twists.
I typed "croissant meaning" in Google and received Cambridge Dictionary as the ultimate source for this popular query. Then I put this top predator to SEMRush and pulled some of its top competitor's SEO Data.
To have some variety on my language menu I fetched two sites from the results of the "como se dice patatas fritas en ingles" search as well.
Yes, I was really hungry when doing this research.
Looking at global results I had the following data:
| Site | Organic Traffic | Organic Keywords | Indexed Pages |
|---|---|---|---|
| https://dictionary.cambridge.org/ | 673.1M | 14.8M | 3.3M |
| https://www.merriam-webster.com/ | 748.1M | 15.6M | 11.3M |
| https://www.collinsdictionary.com/ | 275.2M | 16.5M | 3.8M |
| https://www.ingles.com/ | 43.5M | 4.9M | 1.5M |
| https://www.linguee.com/ | 25.3M | 8.2M | 748K |
Even the smallest players were big enough in terms of the number of URLs and the amount of traffic to find some interesting stuff.
So I checked the top-performing paths, pages, and keywords of the selected sites and to my surprise, I found some patterns.
1. Internal links everywhere
Internal links can have a considerable if not the biggest impact on SEO Visibility for websites of considerable size.
- How are dictionaries making sure to let Googlebot access every important URL?
- How are dictionary entries passing Pagerank between URLs?
- How are they inserting the number of links they need without hurting the User Experience?
Without accessing individual dictionary entries Google wouldn't index anything meaningful, while without internal links these entries would have significantly less chance to rank in search.
It looks like the top dictionaries are aware of these and they are utilizing different types of internal links.
Phrases Containing
Adding a list of phrases that contain our searched query in a different context, in a longer form is not just good for dictionary users but they come in handy if the words are properly linked.
And they are.

This section can be pretty powerful for shorter words.
Just look at what happens when we check what we have after the See More button:

When every word is a link
On the dictionary section (/dictionary/ subfolder) of Merriam-Webster, we have some other words linked in the main content.
The uppercased words are usually leading us to another dictionary entry.
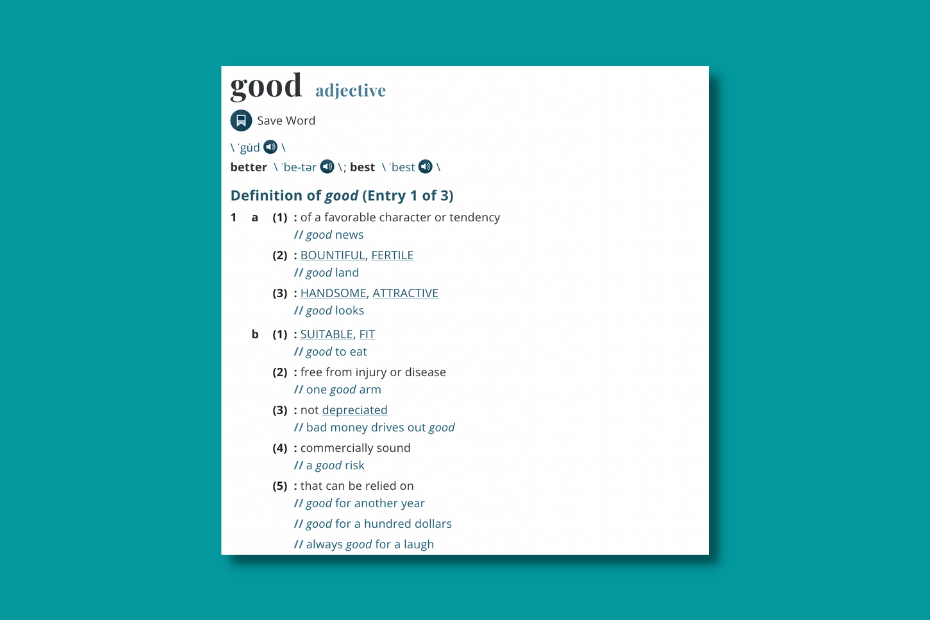
But the synonym section of the site takes this to the next level.
Partially because of the design of the page (there is less focus on making every entry separated),
The good entry in thesaurus links to 1847 other pages in total (the dictionary entry has 680 outlinks).
Some site owners would consider this page as a good sitemap.

The Alphabet & Browse Pages
Almost all of the examined sites are using internal links to nearby entries. The number of links they add this way to pages is not as drastic as we saw with the methods above, but there is a trick.
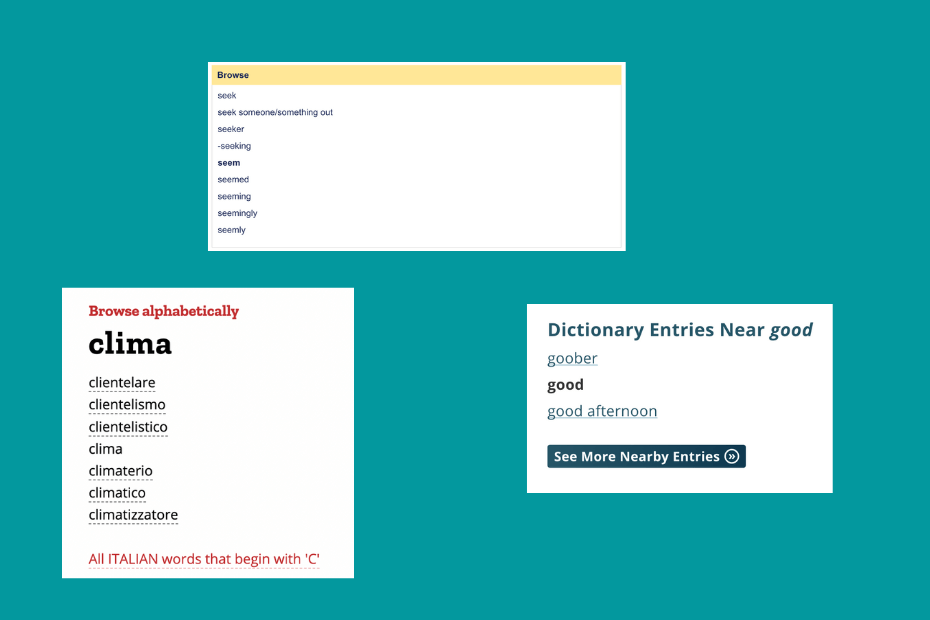
Instead of hiding more links behind a tab, most blocks have a link to an HTML sitemap like Browse page.
The sole purpose of these pages is to interlink entries.
And they are doing it very well with the following functions:
- alphabetically nearby entries are listed with links
- pagination is utilized to keep these pages short & user-friendly
- they are linking to other letters
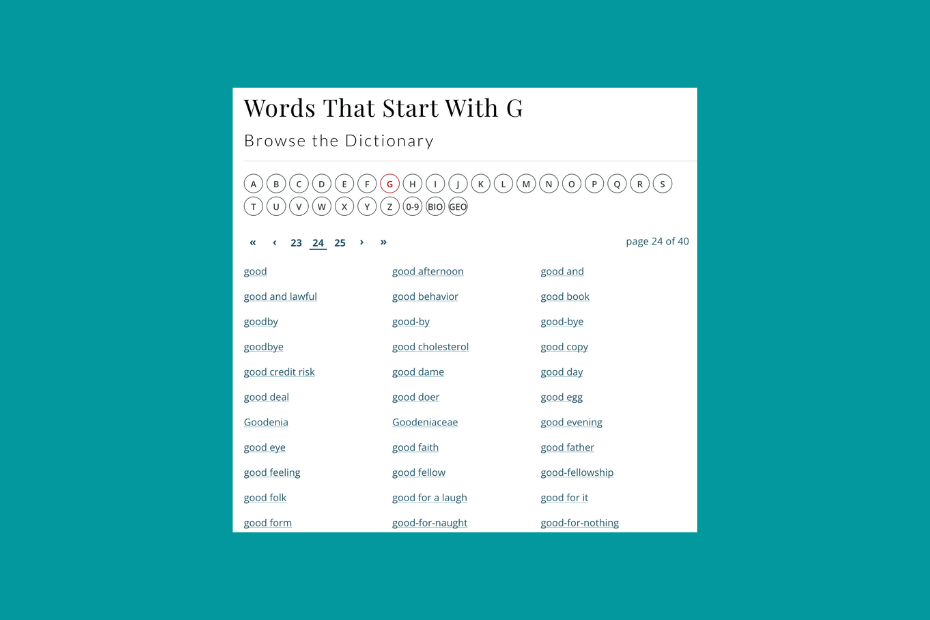
Obviously, browse pages consume some crawl budget without providing much traffic, but dictionary entries get more chance to be crawled and drive traffic this way.
Popularity-based internal links
Linguee.com is built differently from the other sites we examined. Also, it has fewer pages (748K) than any of the other mentioned sites.
The big players are uniting every dictionary entry within one domain, while Linguee is splitting them into subdomains based on language and focus linking only content within the subdomain.
They have:
| Site | Organic Traffic |
|---|---|
| Linguee.es | 48.0M |
| Linguee.com.br | 37.4M |
| Linguee.com | 25.3M |
| Linguee.de | 19.0M |
| Linguee.hu | 122.1K |
...and many more, but finding them is difficult since they are not interlinked.
While Linguee is using links in the content for other word entries, they are lacking the phrases contained and the letter-based nearby entries.
Instead, they have browse pages for
- Current searches
- Most frequent dictionary requests

I suspect they use some magic in the background like weighting what gets into this block based on the frequency of internal searches or search volume, but still, the amount of links we see on a dictionary entry is relatively low.
The "Most frequent dictionary requests" are much more thorough. They are the browse page of Linguee, but the order is not alphabetical in their case.
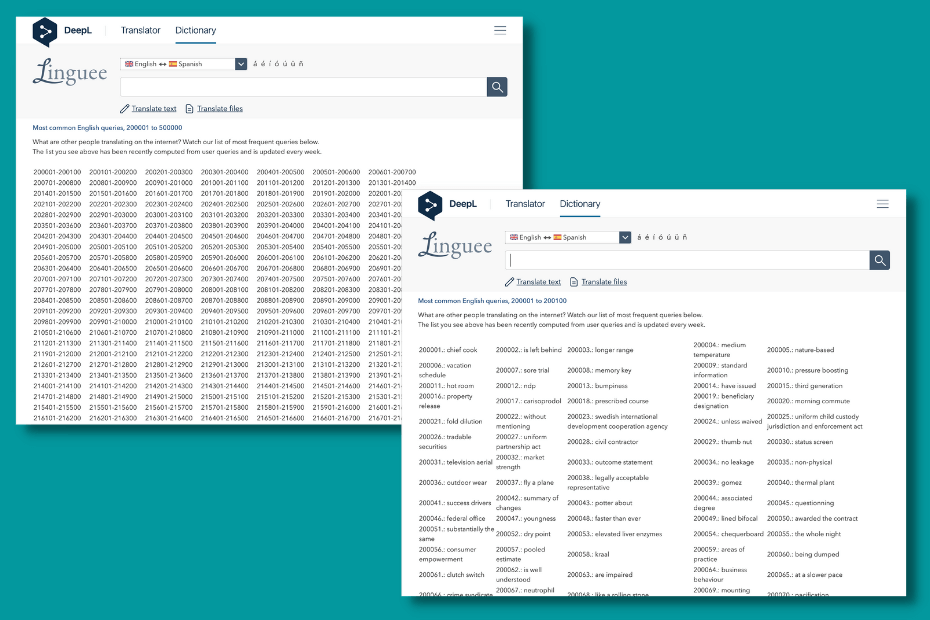
2. Search intent, page structure, page titles
The content that dictionaries have can be relevant for several different types of keywords. Also, the intent of these keywords varies based on what the user is looking for.
Sometimes reading a one-sentence excerpt is enough for the searcher (zero click danger!), other times they need more context, examples, articles, or audio content.
I identified the following main type of keyword patterns that dictionaries are ranking for:
- Dictionary, Translator (f.e: translate english to spanish)
- Meaning, definition (f.e: encanto meaning)
- Synonyms (f.e: hand made synonyms)
- Pronunciation (f.e: how to pronounce salmon)
- Examples (f.e: desolate in a sentence)
- Grammar (f.e: linking words in english)
Unified content or separate pages
Most of the dictionaries have content for the first five keyword types. The main difference between them is how they are presenting this data.
Merriam Webster is targeting these keywords with two page template:
The dictionary entries are meant to rank for meaning, pronunciation, and examples in the case of MW. The entries contain all of them as a big summary page.
The thesaurus subfolder is targeting the synonyms.
The Cambridge Dictionary is targeting the same keywords with separate pages.
- The /dictionary/ templates are meant for meanings and definitions.
- The /pronunciation/ for "how to pronounce" keywords.
- The /example/ for "X in a sentence" keywords.
- And of source we have /thesaurus/ here separately as well.
The Cambridge approach enables them to use SEO-optimized page title and meta description templates for at least 3 types of keywords instead of targeting only one with dictionary entries.
And they are taking advantage of the possibilities page title optimization provides by shaping the template to match exact match keywords.
| Page type | Title |
|---|---|
| Dictionary | EXAMPLE | meaning, definition in Cambridge English Dictionary |
| Pronunciation | How to pronounce EXAMPLE in English |
| Example | selective exposure in a sentence | Sentence examples by Cambridge Dictionary |
| Thesaurus | conflict - Cambridge English Thesaurus with synonyms and examples |
Some observations on the Cambridge Dictionary page title templates:
- Dictionary entries have both popular match case endings: meaning, definition.
- Pronunciation pages have the popular query starter: how to pronounce.
- The example page targets "X in a sentence" and "sentence examples" as well.
- Thesaurus has synonyms and examples in the title.
Ingles.com has a similar approach to the Cambridge dictionary:
- https://www.ingles.com/verbos/satisfacer
- https://www.ingles.com/ejemplos/satisfacer
- https://www.ingles.com/pronunciacion/satisfacer
- https://www.ingles.com/sinonimos/satisfacer
While the Collins Dictionary is rather following the "Kill two birds with one stone" mentality similarly to Merriam Webster.
3. User-generated content
On two-sided marketplaces, user-created content makes or brakes SEO gains just as is described in the Cold Start Problem.
But this shouldn't be the case for dictionaries since they are working with static sources (this can be also why their rankings are fairly stable compared to sites that rely on UGC).
But still, we find sections, where UGC is enriching the site or even users, can create indexable dictionary entries.
Comments
On Merriam-Webster entries, users can add comments about why they are looking for the word in the first place. The block is Client-Side-Rendered but still, it is potentially a good way to add extra relevant text to shorter entries.
Though the moderation of comments at the scale of these websites is a mystery to me.
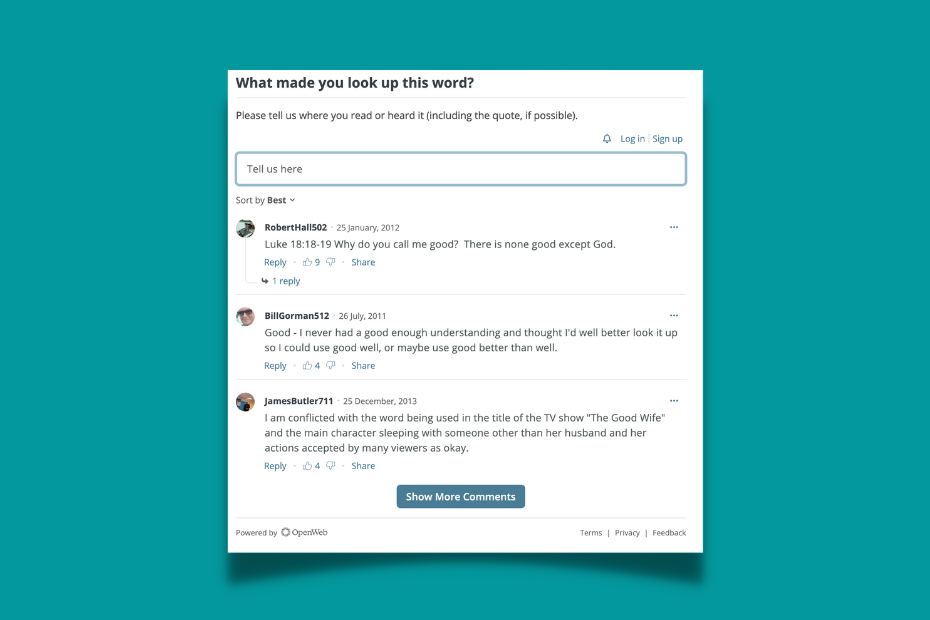
Submit your word
What happens when you are looking for a word's meaning but none of the dictionaries have it? What should the dictionary do to capture the search demand these new words create?
The Collins Dictionary found a clever way to solve this problem while gaining some SEO Traffic.
They let users submit new words.
The page titles for these pages are on point (similar to dictionary entries), they have internal links pointing to other submissions, and there is a browse page for these entries as well.
Submissions are ordered in different language subfolders, so the total traffic can be much bigger, but the /us/submission/ has approximately 346k organic traffic based on SEMRush.
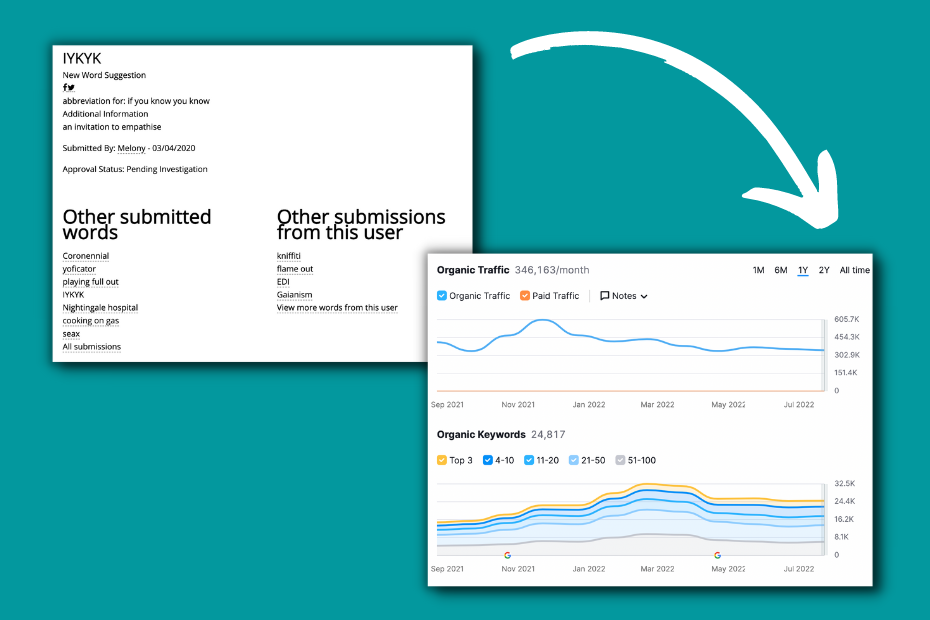
4. Schema markups
The majority of the examined sites didn't use anything new or fancy. They are sometimes not using schema at all, or adding Website, Article, or Organisation schema.
Merriam Webster is adding something more on the front of structured data as well.
For a dictionary entry they are adding the following types:
- WebPage
- WebSite
- SearchAction
- DefinedTermSet
- DefinedTerm
- AudioObject
<script type="application/ld+json">
[{
"@context": "https://schema.org",
"@type": "WebPage",
"name": "Definition of manifest",
"url": "https://www.merriam-webster.com/dictionary/manifest",
"description": "Definition of 'manifest' by Merriam-Webster",
"isPartOf": {
"@id":"https://www.merriam-webster.com/#website"}
,"relatedLink": [
"https://www.merriam-webster.com/dictionary/manifest%20destiny" ]
},
{
"@context": "https://schema.org",
"@type":"WebSite",
"@id":"https://www.merriam-webster.com/#website",
"url": "https://www.merriam-webster.com",
"name": "Merriam-Webster Dictionary",
"potentialAction": {
"@type": "SearchAction",
"target": "https://www.merriam-webster.com/dictionary/{search_term_string}?utm_campaign=sd&utm_medium=serp&utm_source=jsonld",
"query-input": "required name=search_term_string"}
},
{
"@context": "https://schema.org",
"@type":["DefinedTermSet","Book"],
"@id":"https://www.merriam-webster.com",
"name": "Dictionary by Merriam-Webster"
},
{
"@context":"https://schema.org",
"@type": "DefinedTerm",
"@id": "https://www.merriam-webster.com/dictionary/manifest",
"name": "manifest",
"inDefinedTermSet": "https://www.merriam-webster.com/"
}
,{
"@context":"https://schema.org",
"@type": "AudioObject",
"contentURL": "https://media.merriam-webster.com/audio/prons/en/us/mp3/m/manife01.mp3",
"description":"How to pronounce manifest (audio)",
"encodingFormat":"audio/mpeg",
"name":"manife01.mp3"
}
]
</script>Marking up the pronunciation mp3 file with schema is clever.
What was totally new to me are DefinedTermSet and DefinedTerm.
Based on schema.org we got the following definition for them:
- DefinedTermSet: "A set of defined terms for example a set of categories or a classification scheme, a glossary, dictionary or enumeration."
- DefinedTerm: "A word, name, acronym, phrase, etc. with a formal definition. Often used in the context of category or subject classification, glossaries or dictionaries, product or creative work types, etc. Use the name property for the term being defined, use termCode if the term has an alpha-numeric code allocated, use description to provide the definition of the term."
So these are schemas created for dictionaries and Merriam Webster is already using them.
The impact they can have by using new and less documented schemas is unclear to me, but maybe they are one of the performing dictionaries in search because of these moves.
5. Crawl Management
We are talking about sites with millions of valuable pages. They have to think not just for search engine bots that can make or break a website at that size, but for opportunists trying to scrape and reuse their content.
Big dictionaries are not like the typical eCommerce site you can crawl and analyze on Saturday afternoon. In fact, you can't even put most of them into Screaming Frog and receive anything valuable to analyze.
Even if they are blocking crawlers based on user agents or letting through just certain IPs they are definitely doing it right.
Robots.txt
The length of robots.txt varies based on sites.
They usually disallow:
- internal searches
- autocomplete pages
- saved search functions
- signup messages
- login pages
Most of them link their XML sitemap files in their robots.txt.
Also, they sometimes send a clear message to internet wanderers who are thinking of crawling them.
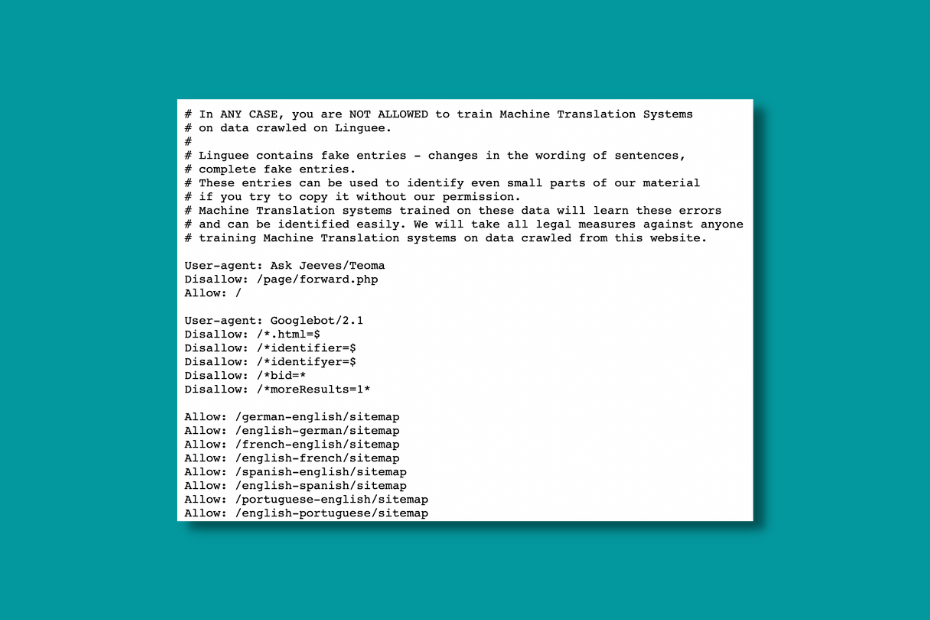
XML Sitemaps
What to say here?
All of the examined sites are using XML sitemaps. They have thousands of them if we count just the ones which are discoverable through robots.txt.
Who knows how many other sitemaps they have submitted to Google Search Console outside of that?
What can be interesting here is that dictionaries don't rely just on XML sitemaps, but most of them have HTML sitemaps like browse pages as well.
Summary
There are a lot of details I slipped through and potentially there is stuff I didn't got it right, but it's okay.
I don't want to make this series a full technical SEO analysis of different websites but rather pick interesting stuff from sites with advanced SEO we can learn from.
So what can we learn from the SEO Patterns of Online Dictionaries?
- If you have a lot of pages use different types of internal links. Long-tail variations, alphabetical order, related keywords, popular searches. You name it, dictionaries have it.
- Use browse pages. They serve as HTML sitemaps but dictionaries are using them in a more clever way. They split keywords into several browse pages. They link browse pages from dictionary entries.
- Think about how you can enrich your pages with user-generated content. Even if you have a big static database you can take advantage of comments or you can fill the gaps for keywords for what you don't have data.
- Find the specific schema relevant to your site and use it. Even if you don't see an immediate use case for the schema, enriching your pages with structure data can help search engines connect the dots.
- XML sitemaps are a must for big sites. All dictionaries use them though most of them have great HTML sitemaps as well.
I hope you enjoyed reading this analysis as much as I had fun writing it.
If you want to have the next pieces of the series where we go through the SEO Patterns of
- News Publishers and Magazines
- Software Review Sites
- Job Boards & Job Marketplaces
then you can subscribe below and I send them to your inbox.



