SEO Patterns for News Websites
Analyzing publishers with hundreds of millions of clicks is a great way to learn SEO. Search Engine Optimisation for News is unique. Google News & Discover are enormous traffic magnets. So let's check what the most prominent publishers are doing to leverage these opportunities!


News SEO is outside of our comfort zone for many of us. We have more opportunities in this field than doing keyword research and generating evergreen content to answer the questions of searchers.
Indeed the biggest opportunities for news are outside of traditional SEO.
As an outsider (without access to Google Search Console or Analytics), SEOs became pretty good at reverse-engineering the organic search playbook of websites appearing in Google search.
But this is nearly impossible for news sites.
We have 3rd part tools like Ahrefs, Sistrix, SEMRush, and more to analyze the best-performing page templates and content of websites.
This works partially for news publishers, but we lack a big slice of the pie:
- Google News
- & Google Discover traffic.
And the latter two are often a bigger contributor to the SUM of traffic than clicks from regular searches.
(I know, without seeing a GSC account of a big publisher this is hard to believe)
It would be so cool if @Similarweb @semrush or @ahrefs could give us estimated Google Discover or Google News traffic of sites.
— Norbert Híres (@NorbertHires) September 22, 2022
Why analyze SEO patterns of News Sites
With the SEO Patterns series, my goal is not to nerd out on what big websites are doing with their SEO strategy, but to discover what we can learn from them or actually do better.
Publishers have some unique strengths when it comes to why they are worthy to analyse:
- Size of the site: With years (or decades) of publishing an insane amount of content daily, the biggest publisher has to take care of how Google crawls and finds its content and most importantly: how fast can Google find a new article. How do they handle pagination, tags, author pages, and archives to give a shot for older articles but keep the size of the site manageable?
- SEO is becoming more visual: There are more images shown on Google than before. Also to be able to appear in Google Discover images are crucially important as well. What are Google's recommendations in terms of image sizes, markup, and what news publishers (for whom images are even more important) are using?
- E.A.T: Google is fighting to show authoritative and trustworthy content from experts in the search. Your outsourced SEO-optimised articles without E.A.T in mind don't cut it anymore in search. Authors on news websites are writing about highly important topics which can influence elections, investment & life decisions. I bet they got E.A.T right and we can learn from them how to do the same.
- Tools & Guidance from Google: News is important for Google. G wants to show the best possible results in the least amount of time after it gets published. To enable this Google gave us tools (News Performance Report, AMP bye-bye) and published guides (Article Schema, Paywalled content). Though these resources are not just for news publishers and we can use them to get the most out of search.
The Landscape of News Websites
In the last edition of SEO Patterns, I selected dictionary websites to analyze based on just overall SEO traffic with some variations.
Now I selected some of the most popular publishers based on brand searches.
I think popularity is a good predictive element of size in this industry.
With the most popular brands, I also select brands that are around for a while and published a significant amount of articles.
| Keyword | Monthly Search Volume (US) |
|---|---|
| cnn | 24.2M |
| cnbc | 2.9M |
| bbc news | 2.2M |
| nbc news | 1.8M |
| new york times | 1.6M |
| npr | 1.2M |
| cbs news | 992K |
| al jazeera | 300K |
Though this is not some strange analytical experiment.
I let my curiosity drive me and selected CNN, BBC, and The New York Times to analyze at the end.
| Site | Organic Traffic | Organic Keywords | Referring Domains |
|---|---|---|---|
| https://www.bbc.com/ | 167M | 34.2M | 804K |
| https://www.nytimes.com/ | 354M | 27.5M | 1.5M |
| https://www.cnn.com/ | 98.9M | 19.9M | 935K |
They are big enough to be worthy of analysis and also we got some variations in traffic which makes them distinctive enough to have some difference in what they do in SEO.
SEO Patterns for News Websites
1. URL and Site structure
Sections, subsections, tags
What categories and subcategories are for e-commerce websites are sections and subsections for new publishers (or at least for the examined three sites).
Also in some cases, we have a one-level deeper tag like pages.
CNN has sections, subsections and specials which are logically inserted under the subsection but they don't follow the same URL structure:
- Section: https://edition.cnn.com/business
- Subsection: https://edition.cnn.com/business/success
- Specials: https://edition.cnn.com/specials/success/invest-ahead
On the home page, all the sections are linked in the top bar, while on the section pages the menu has links to subsections. It's a great way to signal importance.
The New York Times operates with a similar model, but it has a /section/ subfolder which makes it easier to spy on the size and the estimated organic traffic of these pages.
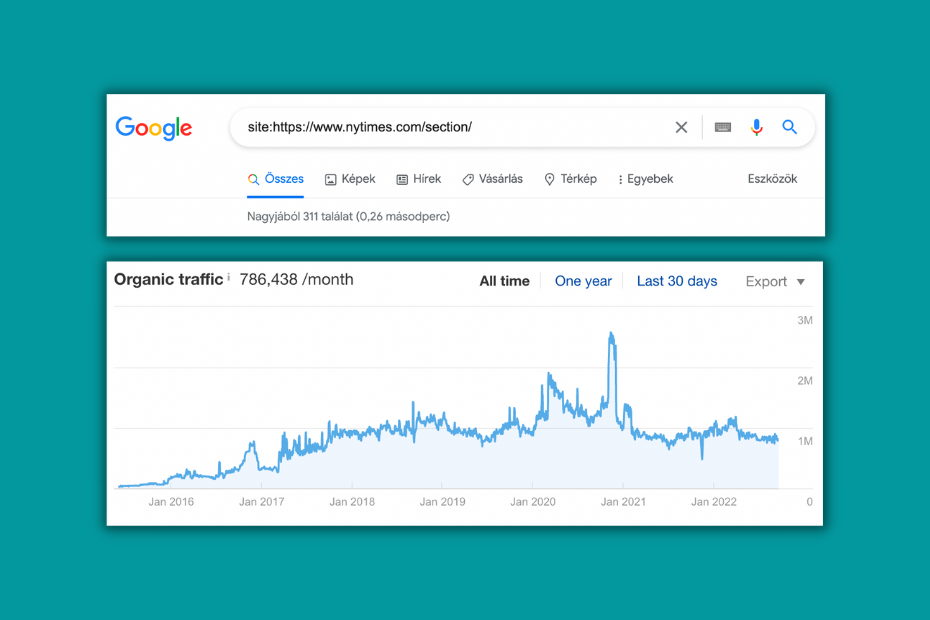
Though most of the time we have two-level deep section-subsection pairs, some top sections list others as their subsection (Business links to Technology).
The connection is signaled by internal links while they are on the same level in terms of URL structure.
- Section: https://www.nytimes.com/section/business
- Section (and subsection): https://www.nytimes.com/section/technology
- Special: https://www.nytimes.com/section/technology/personaltech
Also, some sections simply broke with the /section/ subfolder and go rogue:
BBC put much more emphasis on individual tag pages (what CNN and TWYT are missing).
BBC has a similar section subsection structure with a clear 3rd level:
- https://www.bbc.com/sport
- https://www.bbc.com/sport/football
- https://www.bbc.com/sport/football/transfers
but under the news section, it looks like they are utilizing many more tag-like pages.
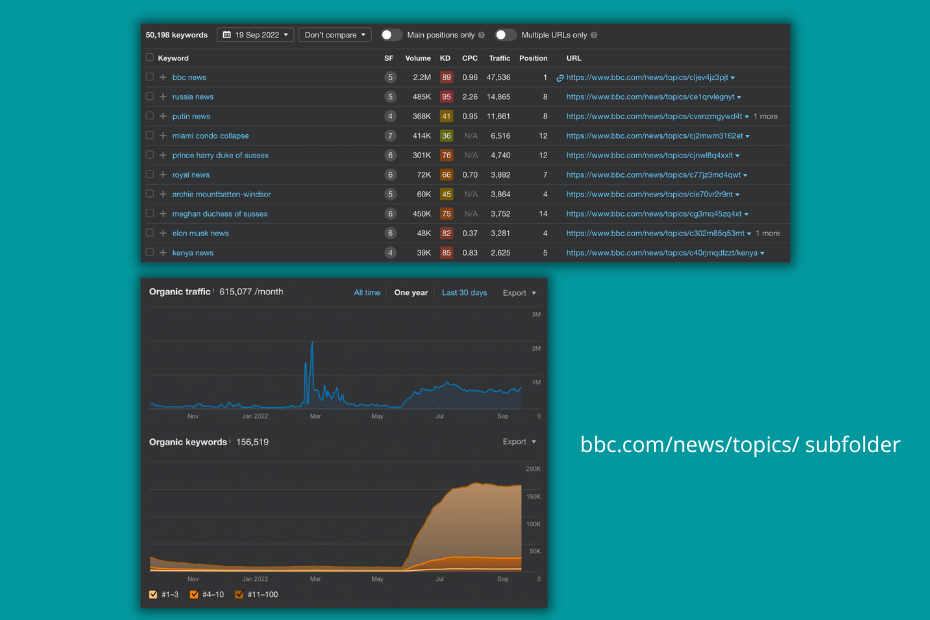
While the other two players are relying on the top menu and the footer to provide links to collection pages, BBC has some automation in place under every article to link to Entities that are put in the bbc.com/news/topics/ subfolder.

While this is a clever move to signal expertise on narrower topics like Censuses in the United Kingdom or the UK Royal Family, these pages are also ranking for "person + news", "country + news" and in general "entity + news' keyword combinations and they drive traffic to the site.
Article URL Structure
The main asset of publishers are articles.
They link articles from the home page, sections, subsections, tags. They are adding them to XML sitemaps and in some cases to RSS feeds.
But what is the structure of their URLs?
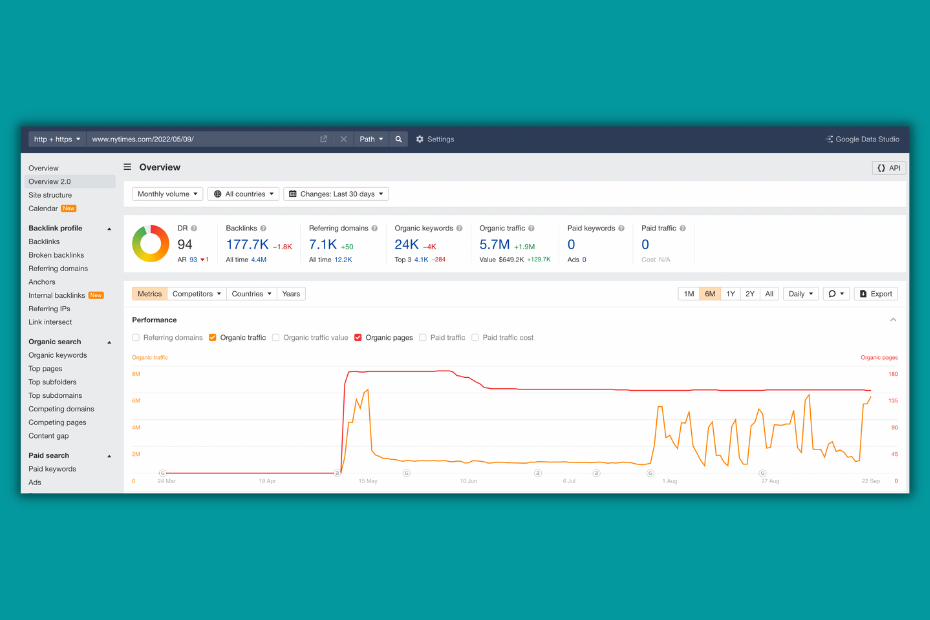
CNN and The New York Times are using "Date + section" structure.
This way we can see the top performing articles for a given day by checking the subfolder in Ahrefs but it is tricky to do the same if we want the top performing article of a section.
For example:
- https://www.nytimes.com/2022/05/09/crosswords/a-note-about-todays-wordle-game.html
- https://edition.cnn.com/2022/09/17/health/armani-williams-autistic-nascar-hf-trnd/index.html
For news BBC has "Section - ID" structure:
For articles in tematic sections like sport or travel, the URLs contain the section path (better opportunity to spy on traffic):
- https://www.bbc.com/travel/article/20220912-four-health-conscious-cities-putting-pedestrians-first
- https://www.bbc.com/sport/football/62950377
Which is the better?
If we exclude analytics considerations then I don't think there is a best candidate.
If your URLs follow the section path then it looks like a well-siloed topic cluster, but in reality I think internal links matter more than URL structure.
Also these URLs contain IDs instead of SEO-friendly readable URLs.
It can make sense. If they would translate the name of the article to lowercase, hyphened URLs than it could have easily select a URL which are already in use.
The date subfolder though does not have a topical subfolder but they are readable and they can easily be organised into HTML sitemaps based on dates like the one The New York Times is utilising.
Live pages
Readers want to get information as soon as possible and writing an article after the event happens doesn't satisfy our information craving anymore.
For this both CNN and The New York Times have a special page in a special folder. These are the "Live pages".
For example:
- https://www.nytimes.com/live/2022/01/03/technology/elizabeth-holmes-trial-verdict
- https://edition.cnn.com/europe/live-news/russia-ukraine-war-news-09-17-22/index.html
They are adding bits of information after the start of the event and at the end they have an enormous wall of text which shows the progress of the event.
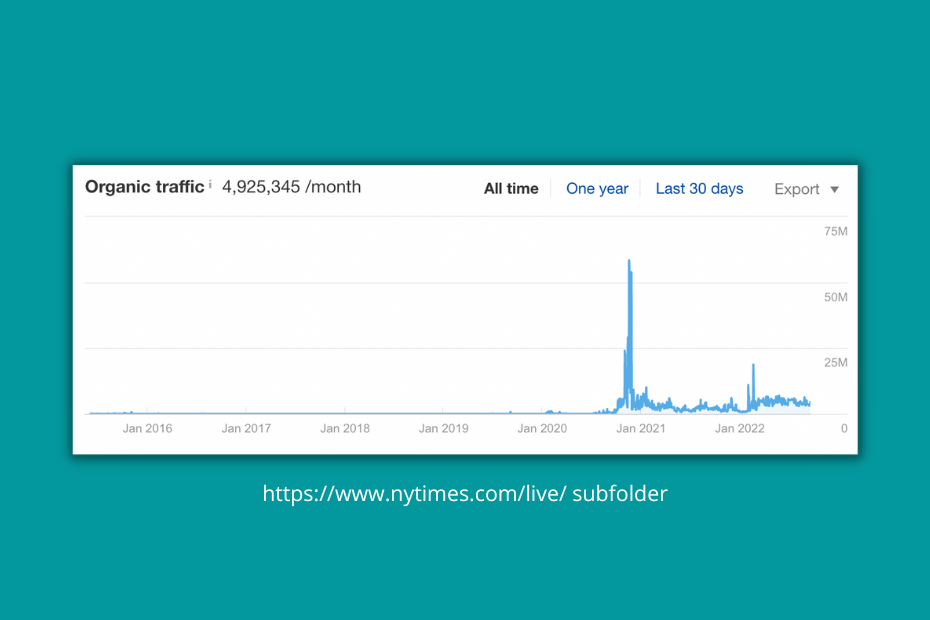
And the sites are storing these URLs which has the possibility to rank over time.
Though because of the nature of search (not much people are searching for the Ever Given issue from 2021 anyomore) the lifecycle of these pages are optimised for the duration of the event.
Maybe this is the reason why we don't see astronomical growth in Ahrefs for the https://www.nytimes.com/live/ subfolder.
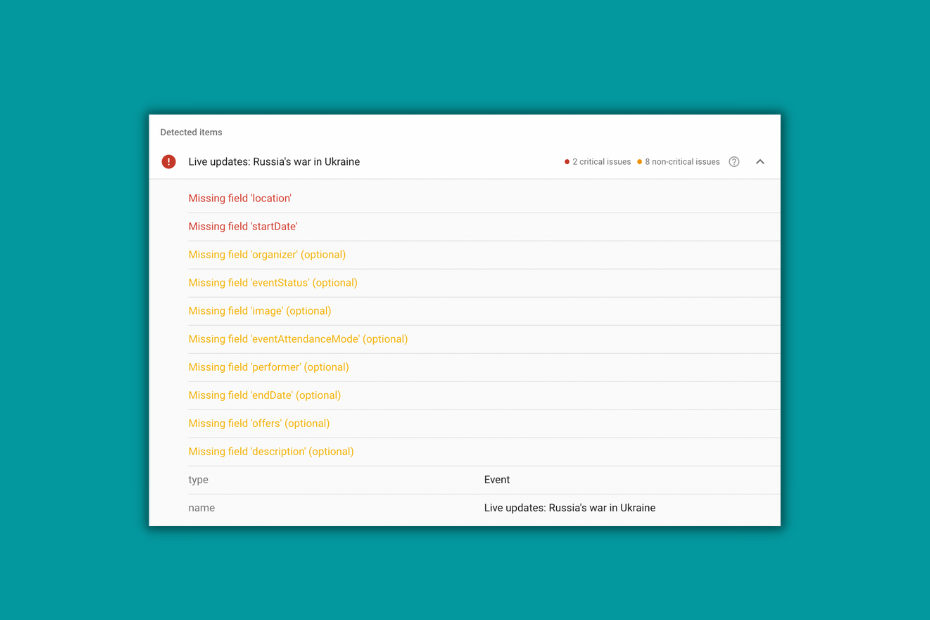
A small caveat is that CNN is adding the "@type": "Event" schema beside NewsArticle schema to these pages though it is missing some necessary attributes.
2. Images
The Google piece on Article Schema and Optimising Images for Google News by Barry Adams are providing a pretty concrete guide on what Google considers best practices for images.
So what we know is that:
- Images should be at least 1200 pixels wide.
- Use high-resolution images (minimum of 800,000 pixels when multiplying width and height) with the following aspect ratios: 16x9, 4x3, and 1x1.
- Include <meta name=”robots” content=”max-image-preview:large”> in the head.
- og:image matters
Though these are suggestions from Google, there are several examples when sites with smaller images or site which doesn't follow any of these elements are thriving in search.
Now let's check what our three selected publishers are doing on the image front:
Image sizes
I did not analyze articles at scale but rather picked and checked one article from each publisher. So it can happen that in some sections the rules are different.
Regarding og:image none of the checked sites are using 1200px+ images, though most of them are above the average 600px wide cover images.
og:images sizes:
- CNN: 800x554
- BBC: 1024x576
- The New York Times: 1050x549
For BBC the images linked in the NewsArticle schema are the same size, but CNN and TNYT are using bigger images in the schema:
- CNN has a 2694x1866 image for the Biden again says US forces would defend Taiwan against Chinese aggression article
- The New York Times has a 1600x900 image for Appeals Court Frees Justice Dept article
Both are well above the suggested 1200px wide cover image.
Max-image-preview:large tag
Adding <meta name=”robots” content=”max-image-preview: large”> to the head gives permission to Google to use bigger resolution images in Google Discover and Google News.
- TNYT has it
- CNN is missing it
- BBC is missing it
What are the implications of the above-mentioned changes in Images?
Maybe nothing for players at the size of CNN and BBC. Or may it happen that more "wide images" are present in Google Discover for The New York Times.
Unfortunately, we can not pull data for this.
What we can do is check some of the posts these brands appeared within Google Discover. For this, we will use the process outlined by David Esteve.
I'm sure that at some point you have asked yourself: How can I know if my content appears in Google Discover with a large photo? You can. Let's go🧵👇
— David Esteve (@DeiviZzZ) October 2, 2021
I checked some topics about which the three sites published recently. Modified the URLs to include the topic and got the following feeds:
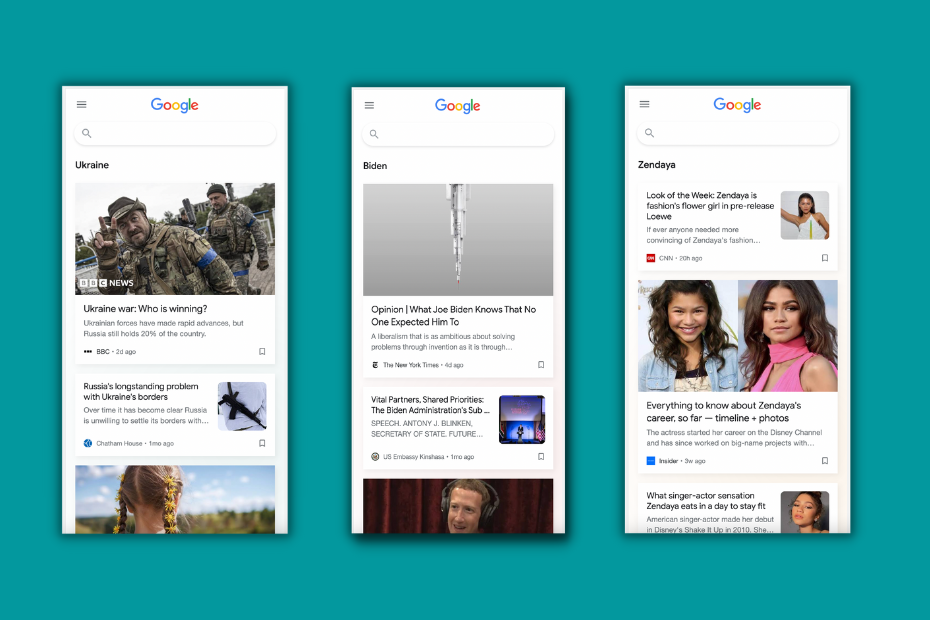
BBC and TNYT have big image placements while CNN is overshadowed by The Insider. Of course, it can happen that for other queries the situation is the reverse.
But a strange coincidence that CNN has the smallest og:image and it is the one appearing with a small thumbnail in Google Discover.
3. E.A.T Signals
The Quality Raters Guideline is really precise on how to evaluate the expertise, authoritativeness, and trustworthiness of both website and creator.
It suggests the following for start:
"Here are the most important factors to consider when selecting an overall Page Quality rating:
- The expertise of the creator of the MC.
- The authoritativeness of the creator of the MC, the MC itself, and the website.
- The trustworthiness of the creator of the MC, the MC itself, and the website."
Besides the authority of the website, the authority of the author is just as important based on this.
This is why I looked into how our selected news sites are displaying the authors of their articles.
BBC
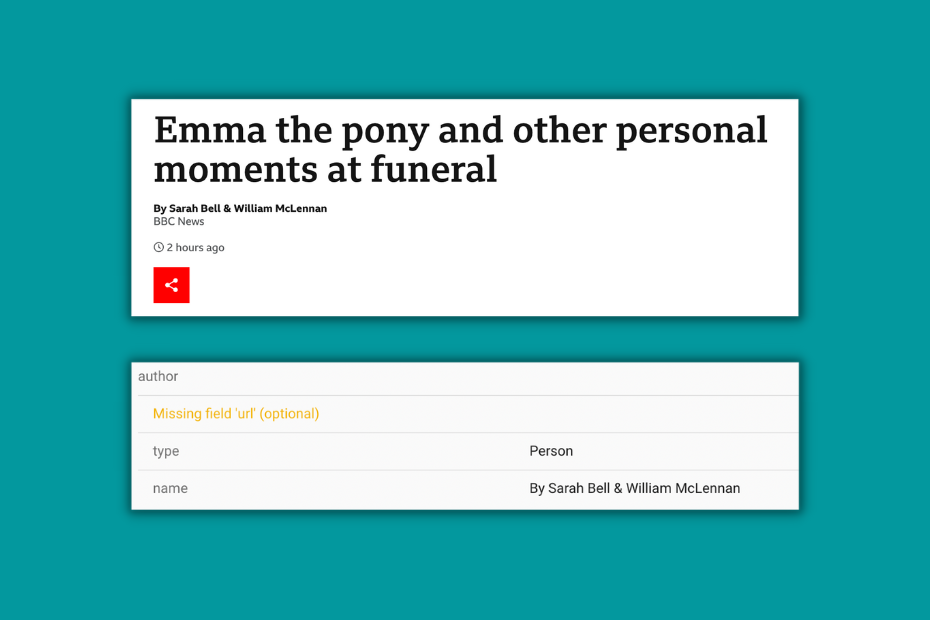
One of the most respected news outlets is doing a really shallow job when it comes to crediting its authors:
- There are no author images
- There is no individual author profile
- There is no link to author profiles whatsoever
- The author's schema is shallow. It does not separate authors and "By Sarah" is probably not the author.
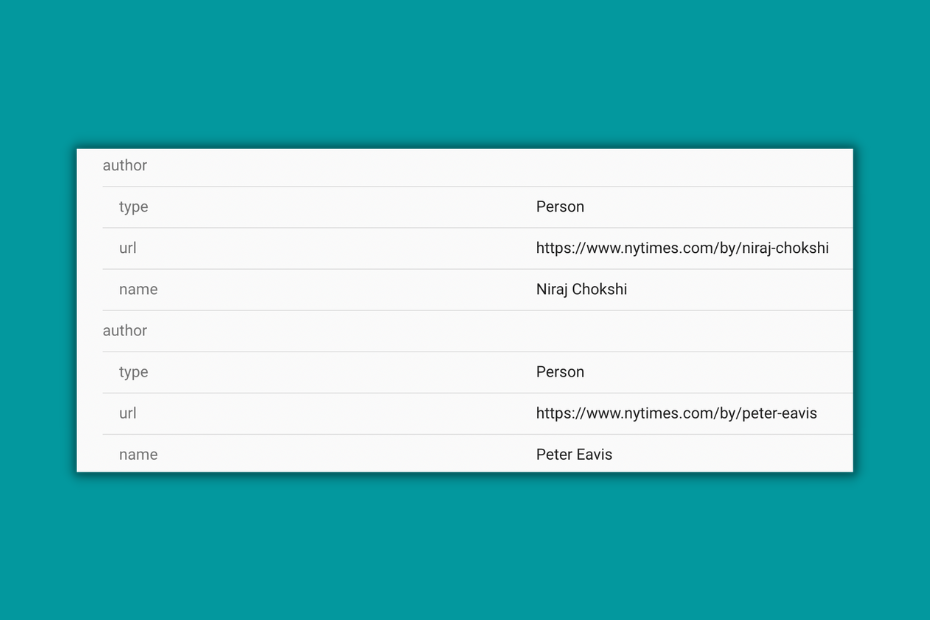
The New York Times
On the other hand, TNYT is a great example of how to create author pages and give credit to authors.

- There are images of the author both in the article and on profile pages.
- There are profile pages with a short bio, articles written, and links to social media profiles.
- The author pages are linked in the article.
- The author schema is separated in the case of articles with several authors and it contains the valid name of the author.
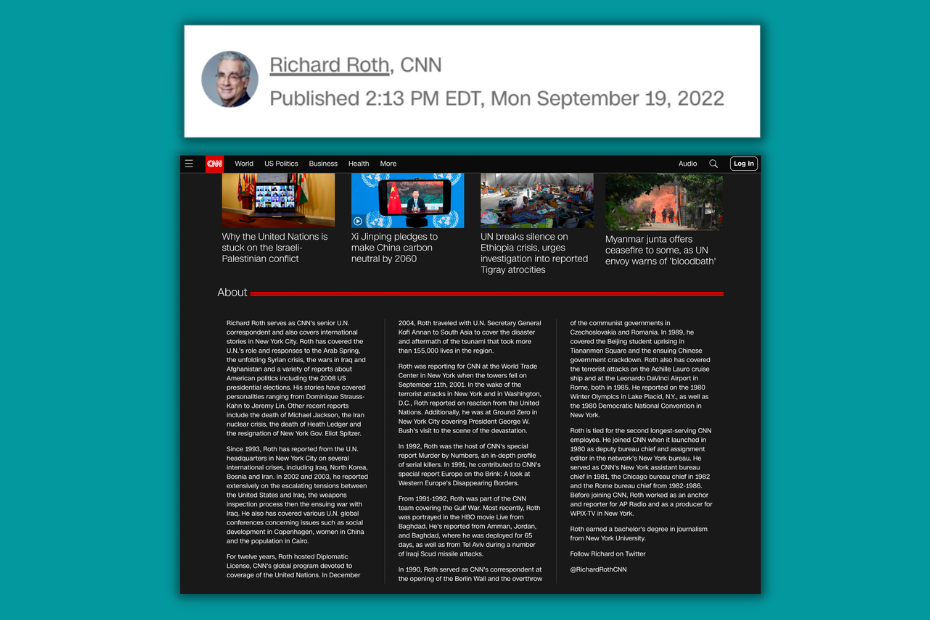
CNN
CNN executes the E.A.T playbook equally well.
Image. Profile. Link. Schema.
Done.
Author profiles are not just a tool to satisfy some silly Google requirements, but are actually useful for the users (I am less likely to read an article if I can't check the writer), and they can drive traffic by ranking for the name of journalists.
4. Paywall and Ads
SEO & Traffic is cool but how does an online publisher make money?
Though there can be more models and there are more monetization channels for the examined sites, for the sake of clarity now we focus on probably the biggest source of income.
- Subscription model: The New York Times tries to convert you with its paywall to paid-subscriber. (Turn off javascript and enjoy the ride.)
- Ads: CNN like most news sites is utilizing display ads.
- Donors: BBC is a strange being because it receives funding from various organizations.
Paywall
The chosen business model arrives with its own challenges when it comes to SEO.
Google can access and understand paywalled content well and it doesn't make a problem showing it in its wide range of products. The Subscription and paywalled content article is a guide by Google on how to handle this type of monetization.
The New York Times is following the guideline and using "isAccessibleForFree": "False", in the Article schema to signal paywalled content.
Does the paywalled content still rank in Google? Yes.
Could it perform better without the paywall? I have no idea.
Ads
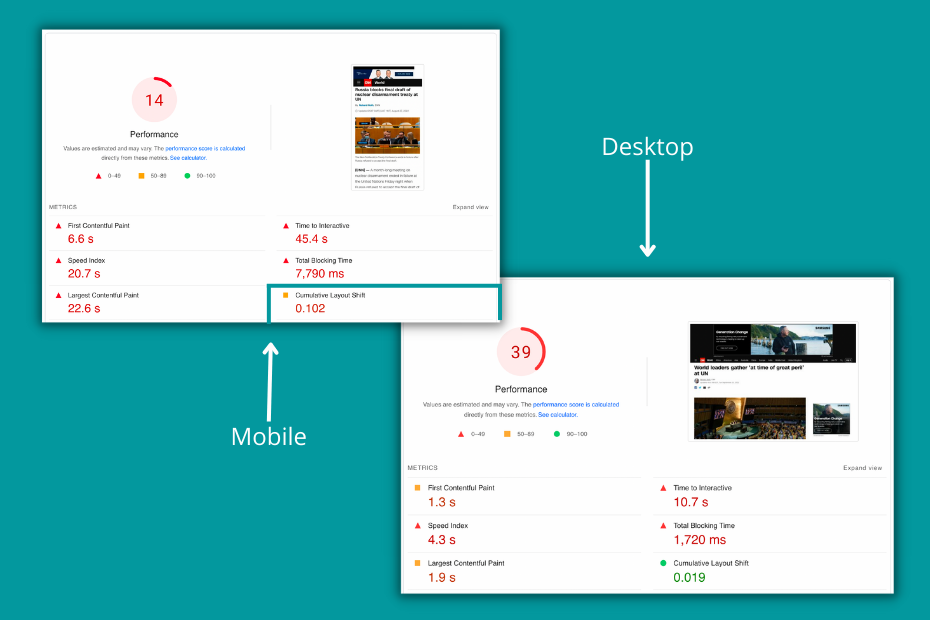
However I still doubt the impact of Core Web vitals on SEO performance, but I will always be grateful to Google for putting annoyingly moving banners on the map by adding Cumulative Layout Shift as a ranking factor to their product.
A site with a good CLS score is not moving, elements (like banners) don't pull down or force to change the position of other blocks.
The good and bad implementation for banners on the top of the page looks like this:
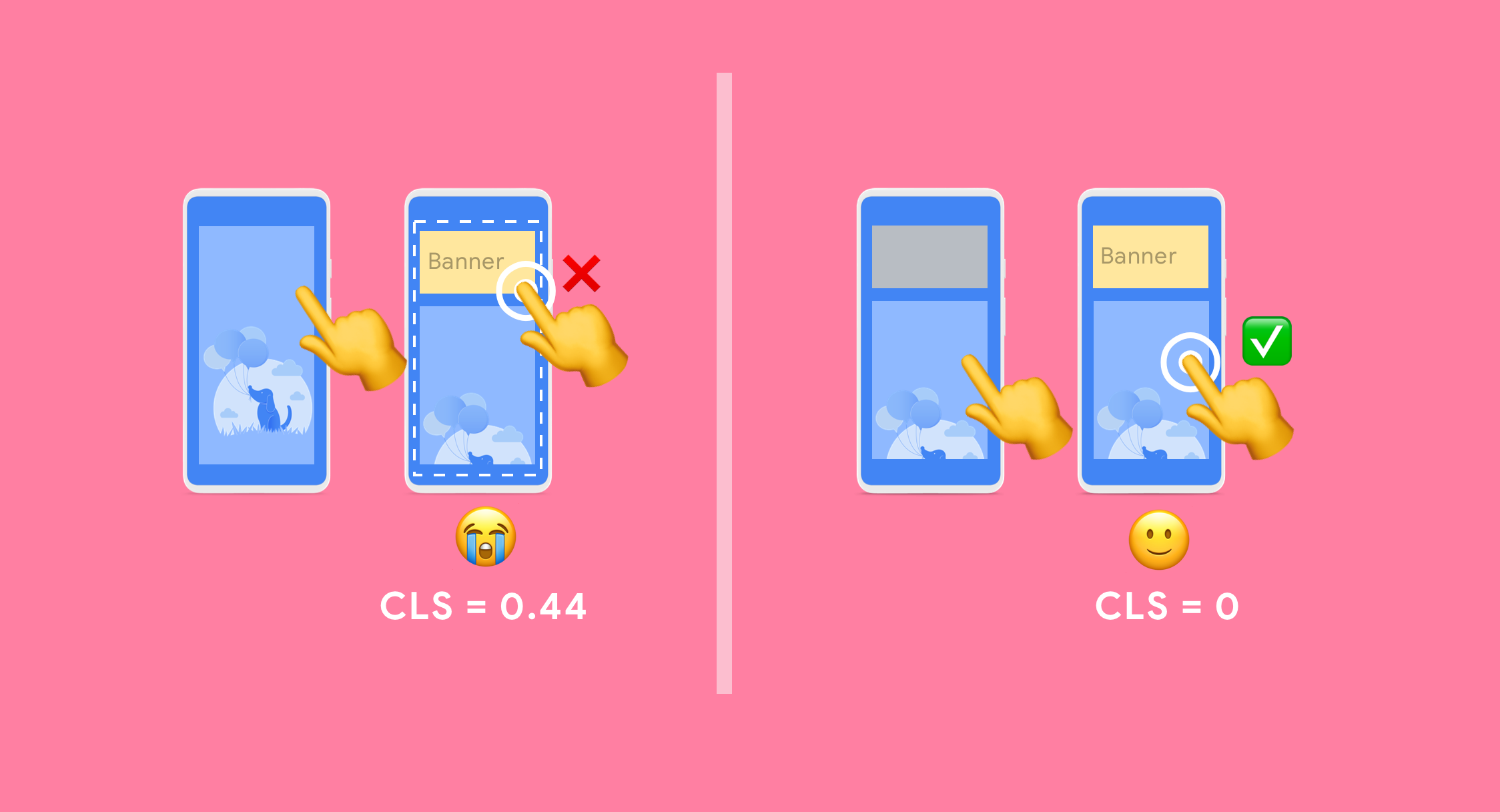
In the best case, we reserve space for the top banners to load in and this prevents the layout shift. CNN is using this best practice for their desktop version, but on mobile, they load the content first, and then the banner is pushing everything down.
This is visible in their different CLS Score as well:
Summary
So as a blogger or site owner in a different industry what can you take home with you after this analysis?
My main learning after analyzing some of the biggest new sites are:
- Use at least 1200px wide images if you want to get into Google Discover. Discover can be relevant not just for news websites.
- Utilize author profiles if you are working with several writers. They can increase E.A.T and you can even rank for the name of the authors.
- Max-image-preview:large tag is nothing to add and can make a difference when it comes to feed-based Google products.
- Even the biggest players are making mistakes. We saw CLS problems, missing author pages, and smaller than suggested image sizes.
This is the third part of my SEO Patterns series.
Read the previous issues and add your email below to get the rest of the series in your inbox:
- The Importance of Patterns in SEO
- Language Learning Websites and Online Dictionaries
- Software Review Sites
- Job Boards & Job Marketplaces



